Executive Summary
Highly available (HA) cloud architectures rarely scale costs linearly. Transitioning from a Single-AZ deployment to Multi-AZ or Multi-Region typically introduces cost multipliers of 2.5× to 6×. This non-linear curve is a primary challenge for FinOps—the discipline aligning engineering, finance, and operations to optimize cloud spend. High availability fundamentally duplicates infrastructure layers, multiplies cross-boundary data transfer, demands idle failover capacity, and explodes observability telemetry. The goal is no longer maximum availability, but cost-efficient availability driven by Unit Economics.
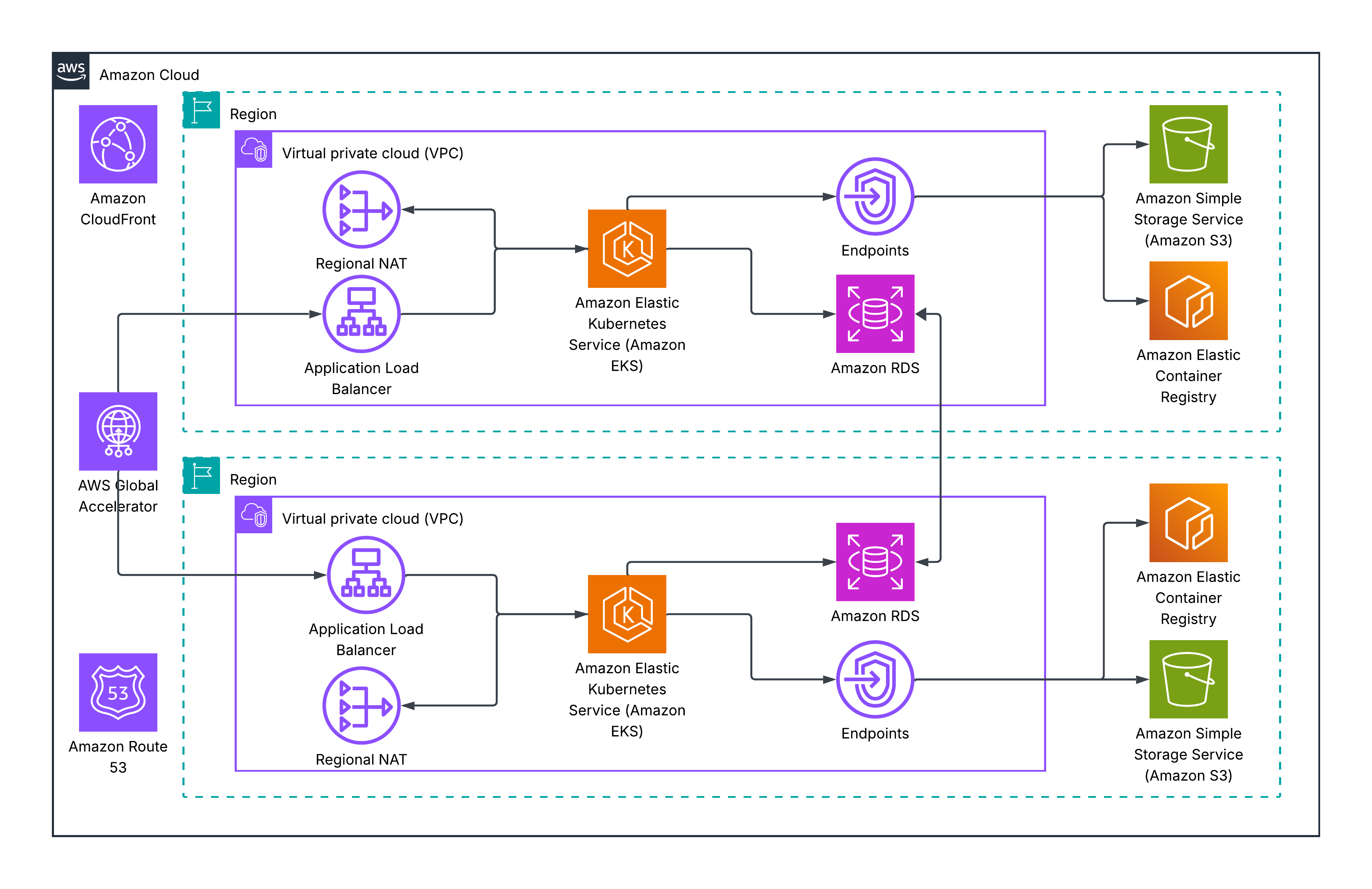
1. The Non-Linear Cost Curve
Theoretical models often assume Multi-AZ simply doubles costs. Real-world FinOps data shows a steeper trajectory:
| Architectural Tier | Typical Real-World Cost Multiplier |
|---|---|
| Single AZ | 1.0× |
| Multi-AZ (Stateless) | 1.8× – 2.5× |
| Multi-AZ + HA Database | 2.5× – 3.5× |
| Multi-AZ + DR Region | 3.5× – 5.0× |
| Active-Active Multi-Region | 4.0× – 8.0× |
To identify these compounding costs, FinOps practitioners must parse granular Cost and Usage Reports (CUR) or adopt the FinOps Open Cost and Usage Specification (FOCUS) framework.
2. Major Cost Multipliers in Highly Available Architectures
2.1 NAT Gateways and AZ Architecture
In a standard Multi-AZ VPC, deploying one NAT Gateway per AZ ensures fault isolation but incurs severe costs. Zonal NAT Gateways levy fixed hourly charges ($0.045/hr) and data processing fees ($0.045/GB), plus standard internet egress fees. While AWS introduced Regional NAT Gateways to automatically span AZs, they offer no financial relief as they are billed per active AZ at the same hourly rate.
Optimization: Aggressively minimize NAT usage by utilizing S3/DynamoDB Gateway Endpoints and AWS PrivateLink (Interface Endpoints) for internal AWS services.
2.2 Cross-AZ Data Transfer
Cross-AZ traffic is an insidious multiplier, costing an effective $0.02 per GB bidirectionally. In decoupled microservices, this can easily exceed baseline compute costs.
FinOps Case Study:
A B2B SaaS company discovered cross-AZ transfer consumed 25% of their AWS bill. They reduced this cost by 80% through three actions:
- Fixing a service mesh bug that endlessly pushed certificates across AZs.
- Modifying Apache Flink logic to partition data locally, preventing 1TB/day of cross-node network shuffling.
- Implementing rack-aware Kafka consumers to read from local AZ replicas.
Optimization: Adopt Cell-Based Architectures to enforce Availability Zone affinity and prevent random cross-AZ chatter.
2.3 Load Balancer Sprawl
Multi-AZ environments frequently suffer from load balancer sprawl, scaling Capacity Unit (LCU/NCU) costs based on connections and processed bytes.
Optimization: Consolidate Application Load Balancers (ALBs) using host/path-based routing. Crucially, disable cross-zone load balancing on Network Load Balancers (NLBs) where possible, as enabling it triggers the standard $0.02/GB cross-AZ data transfer penalty.
2.4 Idle Capacity (The HA Tax)
To survive an AZ failure, systems must provision massive idle failover buffers, regularly driving average CPU utilization down to 15–30%.
Optimization: Shift from static buffers to elastic failover. Utilize AWS Compute Optimizer, which analyzes 32-day metric histories, to ruthlessly right-size instances while maintaining strict scaling policies, and migrate baseline workloads to cost-efficient Graviton processors.
2.5 Database Availability Costs
Database HA is often the largest single multiplier.
- Amazon RDS: Multi-AZ deployments double compute and storage costs by maintaining a synchronous standby replica.
- Amazon Aurora: Separates compute and storage, but introduces variable Input/Output (I/O) costs ($0.20 per million requests on Standard).
Optimization: If I/O costs exceed 25% of the total Aurora bill, FinOps benchmarks dictate transitioning to Aurora I/O-Optimized to eliminate per-request fees.
2.6 The Observability Paradox
Observability platforms frequently cost 2-3× more than the underlying compute they monitor due to data-volume pricing models. Duplicative HA logs and tool sprawl drive this explosion.
Optimization: FinOps targets should limit observability spend to 15–25% of the infrastructure bill. Enforce aggressive log retention limits, utilize dynamic trace sampling, rely on metrics over raw logs, and filter telemetry at the source.
3. Disaster Recovery: Utilization Economics
DR strategy dictates the Recovery Time Objective (RTO) and Recovery Point Objective (RPO), directly altering costs:
| Strategy | RTO (Speed) | RPO (Data Loss) | Relative Cost |
|---|---|---|---|
| Pilot Light | Tens of Minutes | Medium | Medium |
| Warm Standby | 5 to 10 Minutes | <5 Minutes | High |
| Active-Active | Seconds | Near Zero | Very High Base |
The FinOps Paradox: A Warm Standby setup forces organizations to pay for idle, underutilized capacity with 0% customer ROI. Conversely, while an Active-Active setup requires a ~3.57× higher monthly baseline, all infrastructure serves live traffic. If utilization is kept high, the unit cost per transaction in an Active-Active setup can actually be cheaper than paying for idle Warm Standby servers.
4. The Availability vs. Cost Curve
The cost to eliminate downtime increases exponentially:
- 99.9% (8.7 hours downtime/year): Achieved with basic Multi-AZ and managed DBs.
- 99.999% (5 minutes downtime/year): Requires active-active multi-region databases, complex conflict resolution, and global routing. Capturing this final 0.01% of availability frequently costs more than the foundational system itself.
5. Engineering Productivity Burden
Evaluating HA solely on infrastructure invoices ignores the massive operational tax.
Total Cost Formula:
Total Cost = Infrastructure + Engineering Time + Deployment Complexity + Observability Maintenance + Incident Management
Unmanaged dynamic infrastructure often leads to orphaned resources and reduced engineering velocity.
6. FinOps Cloud Unit Economics Framework
Before funding an HA architecture, tie cloud spend to business metrics (e.g., cost per transaction).
- What is the precise financial cost of 1 hour of downtime?
- What is the unit cost per request at each targeted availability level?
- Can the system degrade gracefully (e.g., read-only mode) instead of failing?
- Can we isolate failures using Cell-Based Architecture to limit the blast radius?
Final Key Insights
High availability inflates budgets because it exponentially multiplies infrastructure layers, data movement, and observability ingestion.
The most expensive disaster recovery environment is the one fully provisioned but isolated from serving live customers. Utilization drives efficiency.
True cost optimization is not achieved by buying smaller servers; it is achieved through rigorous FinOps accountability and intelligent, Unit-Economic-driven architecture.
Need Help Optimizing Your HA Architecture?
isaga specializes in FinOps-driven cloud architecture optimization. We help enterprises balance availability requirements with cost efficiency through intelligent design, right-sizing, and Unit Economics analysis.
Calculate Your Potential Savings